





The voice of the state


Abstract
This article is framed by the argument that digital communication is increasingly turning toward audio in contemporary media culture. As part of this shift, visual and haptic interfaces are evolving into aural and oral conversational interactions mediated not through a web browser, but through machines that listen and speak. In June 2025, the EU Accessibility Act has come into effect across all EU member states, mandating that websites and apps implement accessibility solutions, including text-to-speech (TTS) options for citizens who are permanently, temporarily, or situationally unable to read on-screen text. Using the Danish public portal Borger.dk as case study, the article explores how TTS technology affect interaction between public authorities and citizens. Like human voices, synthetic voices convey subtle layers of nonverbal communication such as gender, physical traits, mood, authenticity, trustworthiness, etc. thus, influencing the communication and perception of written content. This raises important questions: Who designs and controls these voices, and is the written content on Borger.dk even suitable for being read aloud? Through the case study, the article examines the concept of synthetic orality in relation to Ong’s notion of orality (Ong 2012, McDowell 2012) as well as the concepts of listening publics (Lacey 2013, 2014) and resonant democracy (Rosa 2021).
Introduction
“[T]he way people interface with technology is in the midst of a paradigm shift from text input and output to voice input and output” (UNESCO, West et al. 2019). This statement still holds true and constitutes the central premise of my forthcoming book Reading with ears and writing with voices: The aural and oral turn in digital communication and media culture (Have, forthcoming), where I trace how born-written media like newspapers, books, letters, notes, e-mails, webpages, and text messages are presently experiencing a surprising popularity in digital audio versions, offering a convenient and effective way to engage with various texts in everyday life. Within this broader discussion of an emerging oral and aural turn, this article focuses specifically on text-to-speech (TTS) technologies that allow digital texts to be read aloud by synthetic, AI-generated voices. Thus, the focus here is not on speech recognition systems, in which machines listen to human commands (think of internet searches, dictations, voice assistants), but machines speaking to humans as vocal agents in a digital communicative satiation. In contemporary digital infrastructures, TTS is rapidly becoming a central interface, and according to a Text-to-Speech Market Report (2024–2029), recent advances in neural networks, accessibility legislation, and edge-AI hardware have transformed synthetic voice “from a convenience feature to a core interface strategy” (Mordor Intelligence 2025) (1). Although the report emphasizes the still limited availability of robust empirical user data to support these developments (see also Keelor et al. 2020), we are all witnessing how synthetic AI voices are becoming almost ubiquitous in everyday digital communication, from GPS, smartphones, and online platforms to voice assistants and smart speakers.
One important driver of this expansion is the global implementation of legal web accessibility acts mandating that websites and apps implement accessibility solutions, such as text-to-speech options for citizens who are permanently, temporarily, or situationally unable to read on-screen text. Within the European Union, the Web Accessibility Directive from 2016 (European Commission n.d. a) has recently expanded through the EU Accessibility Act, which came into effect across EU member states on 28 June 2025 and extended the accessibility requirements from public sector websites and applications to large parts of the private sector, including e-commerce, banking, telemedicine, and digital publishing (European Commission n.d. b). In practice, these regulations have made text-to-speech functionality a central accessibility tool and demand solutions of high quality in different languages and cultures. While originally designed to support dyslexic and visually impaired users, TTS technology has become an increasingly ubiquitous layer in contemporary digital communication.
Voice interaction is also convenient for non-disabled users living modern, busy lives (Have & Stougaard Pedersen, 2016; Engberg et al. 2023; Have 2024). It offers a more organic, transparent, and accessible mode of engaging with digital technology and texts, as voice-operated devices are more immediate compared to their visual counterparts. By virtue of spoken language as an inherently “natural user interface,” users are simply achieving more by doing less (Phan, 2017: 28) when reading with ears and writing with voices. This change of modality from visual to audio reading and writing of texts has consequences for how, why, where, and what we read, and requires especially critical attention to the communicative qualities of voices and voice design – synthetic as well as human.
This article contributes to these broad discussions by focusing on TTS solutions in Danish public e-governance, as exemplified by the national self-service portal Borger.dk (https://www.borger.dk). In a high-trust and digital-by-default welfare state like the Danish, trustworthy, accommodating, and smooth interaction on Borger.dk is considered a democratic necessity when Danes are to fulfil their civic duties and, for example, apply for a new passport, social assistance, or other welfare services. Currently, Borger.dk directs users to the TTS functions embedded in their own devices. Consequently, the voices of Danish authorities are voices designed and controlled by American big tech companies such as Apple and Microsoft, which raises further ethical and critical concerns.
The research question guiding the article is hence how the use of TTS technology and synthetic voices has democratic and social implications for the communication and relation between public authorities and citizens on public digital portals such as the Danish Borger.dk. This includes discussions of synthetic voices’ expressivity, naturalness, authenticity, recognizability, sociability, emotions, gender, and body as phenomenological experiences that may influence citizens’ sense of inclusion and exclusion, their trust and mistrust, and the rights and responsibilities when conducting civic duties through portals like Borger.dk. And should voice design always strive for maximum human-likeness, or are certain texts and genres better served by being recognized as non-human robotic voices, with their distinctive aesthetics of machinic otherness? (suggested by, for instance, Moore 2017a, 2017b; Matthew et al. 2019).
At this point, the analysis is conceptual and not empirical (2). After reviewing existing research (mainly from the field of HCI) on the social and cultural perception of synthetic voices and supplementing it with broader humanities-based perspectives on voice as a medium of cultural meaning, the article proceeds to a case study of the Danish citizen portal Borger.dk. On that basis, it develops a theoretically programmatic framework around synthetic orality as a defining feature of the contemporary oral and aural turn. The article then discusses the social and democratic implications of synthetic orality in light of the case study, drawing on three sound-sociological concepts – sonic citizenship (Andrisani 2017, Højlund et al. 2021), listening publics (Lacey 2013), and resonance (Rosa 2021 [2016]) – to further specify and extend the notion of synthetic orality.
Existing studies of social perception of synthetic voices
Existing research on the perception of synthetic voices is dominated by the field of human-computer interaction (HCI). The studies are usually conducted in laboratories, thus characterized by a lack of context specificity and not reflecting real-world interactions and surroundings (Cambre et al. 2020, 3). Despite the lack of context specificity, these experimental studies can still inform the cultural and social perception of synthetic voices. Another reservation must be mentioned before moving on: TTS technology is advancing so rapidly that a review of existing research does not reflect the present reality. The technological development is simply outpacing academic publishing. Therefore, I will in this review not present previous analyses of specific voices such as Apple's and Microsoft's, since they have changed several times since the studies were conducted. Human perception of voice characteristics and preferences changes too, but is much more stable and viscous, so that is the focus of attention in the following review.
Not surprisingly, research on the perception of synthetic voices suggests that listeners do not experience them merely as technical carriers of linguistic content but as socially meaningful vocal presences. A broad body of research shows that personality judgments of speakers are consistent across listeners (McAleer 2014), and that listeners attribute personality traits and social identities to synthetic voices and evaluate them according to qualities commonly associated with human speakers, such as naturalness, credibility, extraversion, introversion, and vocal persona (Cambre et al. 2000). In a specific study, perceived signals of extraversion and introversion were analyzed, and it was found that people prefer voices mirroring their own personality; meaning that an introverted person will likely evaluate a voice signaling introversion to be more likable and credible than an extrovert voice, and vice versa (Nass and Lee 2001; Nass & Brave 2005).
Newer studies show that voice quality and prosody shape impressions of warmth, stability, or competence (Kim et al. 2024; Kim et al. 2025), and that these perceptions are strongly mediated by social interpretation. Two American studies show how synthetic voices perceived as having non-native accents are often evaluated as less competent or knowledgeable (Jones & Zellou 2024), and how racialized characteristics attributed to voice assistants seem to affect judgments of professionalism and friendliness (Holliday 2023).
Gender cues also structure perception: male-voiced systems are frequently interpreted as more authoritative or secure, while female voices tend to be associated with competence or service-oriented roles, reflecting established expectations surrounding digital assistants (Lee et al. 2000; Mooshammer et al. 2025). An earlier study found that first impressions of vocal attractiveness in male voices relate to perceived strength and dominance, whilst in females, vocal attractiveness relates to perceived warmth and trustworthiness (McAleer 2014, 1). In general, male voices are more likely to receive positive ratings regardless of whether the voice is human or generated by a TTS algorithm (Cambre et al. 2020), and test persons generally perceive male voices or deeper female voices to be more knowledgeable, competent, and trustworthy (Brooks et al. 2014, Nass et al. 2000). Another experiment conducted by Tsantani et al. (2016) confirms the tendency to select the low-pitched voice over the high-pitched voice as more trustworthy, for both genders, but more dominant, for male voices. They conclude that "overall preference for low pitch is a default prior in male voices irrespective of context, whereas pitch preferences in female voices are more context- and situation-dependent" (Tsantani 2016, 1). Also, in a study testing perception of semantically meaningful spoken content compared to rubbish talk (they played the same sentences in reverse), the results reveal an overall preference for low pitch, irrespective of direction of speech, but only in male voices. As an important supplement to the favoritism of deep (mostly male) voices, Cambre et al. found that this bias is regardless of participants’ self-identified gender. In other words, men are not more likely to assign positive ratings to male voices compared to women (Cambre et al. 2020, 7). Another interesting perspective on gendered voices comes from Mooshammer et al., who also studied what they call acoustically gender-ambiguous voices in voice assistants, and they differed negatively from gendered voices across multiple trust dimensions This also included ambiguous voices with an ascribed gender (Mooshammer et al. 2025).
From the stand that synthetic voices are routinely processed through socially meaningful classifications rather than as “neutral” technical signals Baird et al. (2018) did a study focusing explicitly on paralinguistic categorization. They asked 18 listeners to evaluate 13 synthesized voices on traits of perceived age, gender, and human likeness and found that none of the 13 voices achieved complete human likeness or was consistently perceived within a single age frequency band, and none of the voices was tied solidly to its given binary gender. “Voices that have been given higher NB [non binary] values, also showed to have lower human likeliness values” (Baird et al 2018: 8), which somehow aligns with the Mooshammer et al. study (2025). An interesting perspective against the tendency to treat gendered voicing as an inevitable binary choice in synthetic speech, comes from Jørgensen (2020), who argues for a reimagination of the paralinguistics of synthesized voices beyond the binary including training and developing pitch, timbre, pace, and other vocal features using vocal data from many different people to propose a diverse and collective, multivocal voice. Picking up on this, the Multi’vocal Collective (which includes Jørgensen) in an audio article suggests that the generation process of synthetic voices itself may provide an audible example of bias in AI (Collective, 2021).
Most research agrees that the voice of an interface has a profound effect on the user experience and changes the dynamic of the interaction (Nass & Brave, 2005; Cambre & Kulkarni 2019). However, most of the studies are based on words, sentences, or paragraphs, and only a few study longer texts such as audiobooks, newspaper articles, and webpage text. One study focusing on long reads is the study by Cambre et al. In a large-scale study, they evaluated 18 TTS voices and three human voices based on listening experience, comprehension, and perception of clarity and quality. They found that although human voices are generally rated as more natural and pleasant to listen to, several synthetic voices approach human performance in listener evaluations of quality and listening experience. Notably, comprehension levels remained comparable between human and synthetic voices (Cambre et al. 2020, 9), indicating that informational communication like the text on Borger.dk can remain effective even when the voice is perceived as less socially authentic. An interesting and more technical finding in Cambre et al.’s study is that voices got higher ratings when listened to through headphones (Cambre et al. 2020, 7). This is a variable often overlooked when studying audio perception in general (Have 2023 and 2024).
Broader cultural perspectives on synthetic voice perception
In continuation of the review of existing experimental studies of the perception of synthetic voice, I will in this section supplement with some more humanities-based perspectives and distinctions of voice as a meaningful medium in itself. First, I find it useful to distinguish analytically between the concepts of language, speech, and voice. Language refers to the system of semantic meaning encoded in words, speech is the articulated stream of these words, and the voice is the acoustic medium that carries speech. Traditional linguistic approaches have primarily focused on the semantic dimension of language, paying comparatively little attention to the sonic qualities through which speech is delivered; the paralinguistic qualities. Yet the voice introduces layers of non-verbal communication through tone, rhythm, timbre, and affect that shape how spoken words are interpreted. While language refers to objects and concepts in the external world, the voice situates communication within the embodied presence of a speaker. As Lønstrup argues, the voice points toward the space of the body rather than the space of the world (Lønstrup 2004, 14). Similarly, anthropologist Steven Feld describes sound and voice as forming a “bodily nexus” that connects sensation, emotion, and respiration within human communication (Feld 1996, 97). Synthetic speech challenges this relationship between voice and embodiment, raising the question of how listeners perceive voices that no longer originate in a human body but in computational systems.
Another distinction I would like to make is a division of digital synthetic voices into two general categories: robots and cyborgs. By “robot voice” I refer to earlier generations of speech synthesis: rule-based and concatenative systems that either simulate the mechanics of the vocal tract or reassemble prerecorded fragments of human speech (Taylor 2009). These voices are usually intelligible but limited in expressivity, producing the flat, mechanical tone associated with synthetic speech. By contrast, “cyborg voices” rely on large neural networks trained on real human voice recordings (Shen et al. 2018). A cyborg voice is usually trained on a single person’s voice but could also be multivocal, trained on data from many different people’s voices (cf. Jørgensen 2020). An illustration of this is the much-disputed case of the voice actor Susan Bennett, who by coincidence discovered that Apple’s Siri had trained on her specific voice. Another example is the Norwegian newspaper Aftenposten’s use of an AI-cloned voice trained on their most popular podcast host, Anne Lindholm. Her voice is used to read all printed articles aloud as part of the Scandinavian Media Group Schibsted’s focus on audio articles as a strategy to make the newspaper survive (Schibsted 2023). Similar examples of use of AI voice clones are the Swedish Aftonbladet’s use of Maria Bjaring’s voice and Svenska Dagbladet’s use of Eva Johannesson’s voice. All are women younger than 50. Unlike the robot, the cyborg does not merely mimic or reassemble but learns patterns of rhythm, intonation, and timbre, generating speech that can be rather indistinguishable from its human original.
As synthetic voices approach human vocality, and even specific human beings, more subtle aesthetic and perceptual questions arise, and as a third perspective I would like to draw in Freud’s concept of Das Unheimliche, describing the unsettling effect that arises when something familiar suddenly appears strange or alien (Freud 1919). Robotics researcher Masahiro Mori later described a similar phenomenon in the context of humanoid robots, proposing the notion of the “uncanny valley” to explain why entities that appear almost human may provoke discomfort (Mori 1970). A comparable effect has been identified in synthetic speech. When voices sound nearly human but contain subtle deviations in rhythm or timbre, listeners may experience a sense of uncanniness (Diel and Lewis 2024). However, the study by Diel and Lewis concludes that this is not so much the case in relation to synthetic voices compared to human organic voices suffering from diseases:
While distinctively artificial voices can deviate from the human norm without suffering from uncanniness, deviations in organic-sounding voices may quickly become unnerving, for example due to the threat of contamination from infected organic entities. (Diel and Lewis 2024, 8)
The concept of the uncanny voice highlights the fragile threshold between recognition and estrangement, raising critical questions about the aesthetics and ethics of designing voices that mediate human-machine interaction.
The final and concluding perspective I would like to mention in relation to voice perception is the expression of power. Our voices are markers of identity, authority, agency, presence, and social belonging, and cultural discourse frequently frames voice as a metaphor for agency when individuals “find their voice”, “have a voice”, or are “silenced”. Some voices are culturally privileged, as Amanda Nell Edgar describes it in the book Culturally Speaking: The Rhetoric of Voice and Identity in a Mediated Culture (2019), and just as we have cultural standards for bodily appearances, we also have cultural codes attached to voices as, for instance, being a trustworthy, authoritative, sexual, or desirable voice – as substantiated by the studies in the previous section. Thus, mediated and designed voices are shaped by cultural norms that cannot escape privileging certain vocal qualities and identities over others (Edgar 2019). Herein lies another power element: the control of voice design. Mediated voices are constructed, edited, filtered, and composed, so who is (or should be) able to decide how appropriate voices for different communicative contexts should be designed? Whose voices are reproduced, and whose are excluded?
Taken together, these four perspectives support the argument that synthetic voices should be understood not only as technological tools but as communicative actors embedded in social and cultural frameworks. Listeners interpret mediated voices through expectations of personality, gender, age, race, credibility, authority, and mood, and these interpretations shape perceptions of trustworthiness and responsiveness in human-machine interaction. The study of TTS technologies therefore requires attention not only to technical and intelligibility performance but also to the cultural meanings, power relations, and machineness embedded in the design and perception of digital voices.
To meet the need for more context specificity in studies of synthetic voice perception, I will in the following section discuss these issues in a more concrete manner by presenting a case study of specific TTS voices recommended in Danish public e-governance on the citizen portal Borger.dk.
Applying for passport on Borger.dk: A case study
Until December 2024, Danish municipalities, including the Danish Police, had integrated the TTS solution ‘adgangforalle.dk’ (English translation: access-for-all.dk) on their common webpage portal www.borger.dk, so users could download and use it to have the digital text on the pages read aloud by a robot voice. Adgangforalle.dk was a Danish digital accessibility project launched around 2007. It was developed through a collaboration between a special school for adults, a small speech-technology company, a technology center for disabled people, and Aalborg University. The service was discontinued, largely because modern operating systems now include built-in text-to-speech functionality of a quality – also in Danish – that it could not match. From December 2024, the Danish authorities now instead refer to the TTS tools already implemented in either Apple’s or Microsoft’s operating systems on the citizens’ own computers. According to the Danish Agency of Digitization, the law and standards concerning the EU web accessibility act are technology-neutral, meaning that there is no requirement for a website to have an integrated TTS function, but the content must be correctly semantically marked, so that the user’s own auxiliary tools can be used on the website.
As already mentioned, Danes have, compared to other highly developed digital societies, a particularly high level of trust in public institutions, and at the same time Denmark is known for strong digital infrastructure and advanced digital adoption and as a pioneer in the development of digital public sector consultancy and self-service. Well-functioning e-governance is therefore considered a democratic necessity if Danes are to fulfil their civic duties.
Now, imagine you are a Danish citizen who enters Borger.dk to find out how to get a new passport, and for some reason need to get the online text read aloud – maybe you have lost your glasses, maybe you suffer from cataracts, or maybe you just understand oral Danish better than written Danish (3). A natural first step when you enter the page for applying for a passport will be to get a text-to-speech overview of the page named “Apply for or renew Danish passport,” its menus, and how to navigate. (4) To do so, you press Command-A to select all text, and then right-click the mouse to open the menu where you can choose the read-aloud option: Tale (Speech) → Start oplæsning (Start reading aloud). See illustration below.
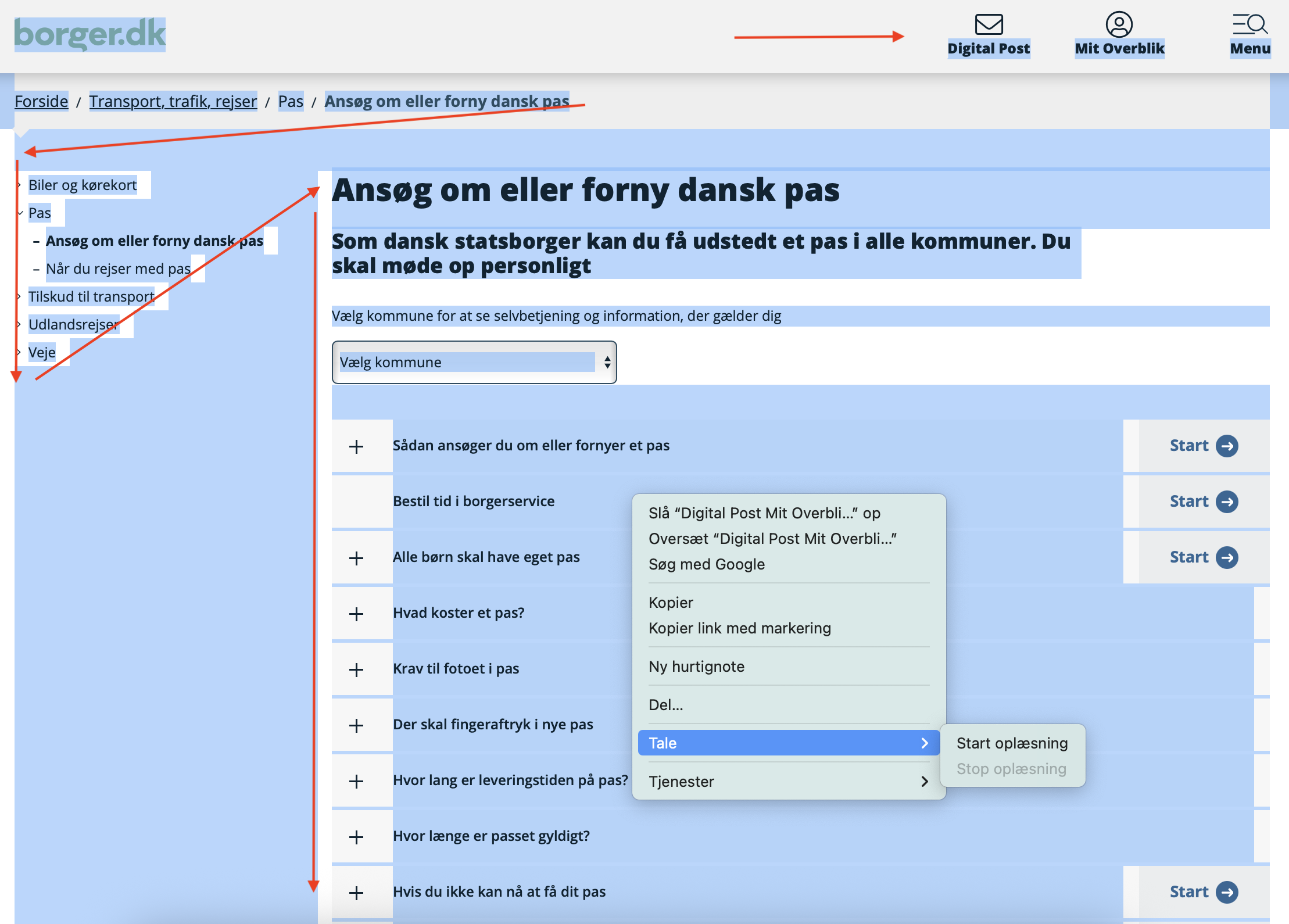
What happens now is that the default synthetic voice in the computer’s operating system will read all the text aloud from the top-left corner, proceeding from the first two lines to the left vertical menu and continuing to the main text in the middle, as indicated by the red arrows in the illustration. On my MacBook computer, the voice that reads the passport text aloud is called Magnus. The Danish female counterpart in Apple/macOS devices is called Sara, and it could also be Siri’s voice you hear, depending on your settings (5).
Though Apple has not publicly documented how those specific voices are built, they are presumably AI-based, relying on large neural networks and trained on recordings of real human speakers. So, they can be characterized as “cyborgs” but are not referring to a living human’s voice, as in the case of Anne Lindholm and others mentioned earlier. The following analysis of Magnus’s and Sara’s voices is framed by the existing research and the cultural perspectives presented in the two previous sections. Some descriptions are based on my spontaneous perception, meaning that others might have other perceptions. However, I refer to previous theories about how metaphorical perceptions and descriptions of abstract sound structures (be they music or voices) are not subjective sensations but embodied intersubjective perceptions that people share within the same cultural frame. That could for instance be experiences of voices as being warm, cold, deep, high, thin, rich, slow, or fast, etc. (Have 2008).
Magnus and Sara are not gender-ambiguous but clearly gendered as male and female, which has a positive influence on the perception of trust (Mooshammer et al. 2025). On first listen, neither of the voices has a discernible accent or dialect, which could have influenced the perception of them as less competent or knowledgeable (Jones & Zellou, 2024) – however, below I suggest they have what one may call a synthetic dialect. The timbre of Magnus’s voice is deep, moderately warm, with only a little rasp, but not as deep or raspy as is common among older men. It can be characterized as a bright baritone, not as dark and weighty as a bass. Sara is rather deep for a female voice. It is soft and mature, alto, not soprano. The deep timbre naturally influences the perception of age (not young) and physical appearance (not slim or skinny). Both voices fall within the category of low-pitched voices measured to be more trustworthy, knowledgeable, and competent than high-pitched voices (Brooks et al. 2014; Nass et al. 2000; Tsantani et al. 2016), which is desirable for a portal like Borger.dk representing the Danish public authorities. Preferences for female voice pitch are often more context- and situation-dependent – in some communicative situations and genres a more girlish, high-pitched voice is preferred – but in a formal institutional setting such as Borger.dk, a deeper female voice is advantageous.
As mentioned earlier, male TTS voices are in general more likely to receive positive ratings than female voices (Cambre et al. 2020), and male-voiced systems are frequently interpreted as mor)e authoritative or secure, while the female counterparts tend to be associated with competence or service-oriented roles (Lee et al., 2000; Mooshammer et al., 2025). Though ‘authoritative’ and ‘secure’ are different qualities than ‘competence’ and ‘service-oriented’, they are all positive in the context of public e-governance. But the Danish authorities are not in control of these differences when they let Apple and Microsoft decide how they orally address the citizens.
As Cambre et al. found in their comparison of human and synthetic voices reading longer texts, several synthetic voices scored higher than human performance in general listening experience. And the level of comprehension remained comparable. This means that synthetic voices can be just as effective as human voices in communicating information. So, as voices carrying non-verbal communicative layers of meaning, Magnus and Sara seem to work relatively well in the Borger.dk context. However, this is certainly not the case for the semantic understanding of the text as speech or language.
At first both Magnus and Sara speak with rather natural variation in pitch and pauses, but when you listen closer the phrasing does not always follow a natural Danish phrasing and accentuation, but instead speaks with a synthetic dialect. Some syllables, for instance ‘pas’ (Danish for ‘passport’), suddenly stand out as extremely highly pitched, which causes a comical effect – most significantly in Sara’s version. Also, an unnatural temporal phrasing and metallic flaws and glitches are challenging the understanding of the text. Since there is a systematic variety of language at stake here, I will argue that it is similar to how we perceive dialects. I therefor suggest the term synthetic dialect, characterized by technologically mediated repeatable patterns in phonology, prosody, syntax, lexical selection, and temporal structuring. Unlike human dialects, which arise from social and geographic variation, synthetic dialects emerge from computational architectures, training data, and algorithmic constraints. They often include non-natural temporal phrasing, as well as characteristic artefacts such as metallic timbre, glitches, or other synthesis-induced irregularities. The term captures system-level regularities that persist across outputs, rather than incidental errors or stylistic choices, designating a structured form of linguistic variation attributable to machine mediation. As a follow-up to Jones’s and Zellou’s study, it would be interesting to test whether synthetic dialect has the same influence on voice perception as human dialects.
An all-important problem with TTS systems at Borger.dk is that the flow of speech cannot distinguish between the different text sections at the interface but simply reads over all the visual layout (see illustration). There are no sonic cues signaling whether the text is a title, a menu, a panel, a list, a button, or a hyperlink, and there is no visible indication of where on the screen the voice is reading or how to activate links, so it is impossible to capture the semantic meaning as a coherent meaningful text. Even if you are able to see the structure and text on the interface, the oral version is impossible to follow. You grab a word here and there, but the aurally transmitted information makes very little sense. I am aware that if you are heavily dependent on these tools – if you, for instance, suffer from blindness – you are likely to employ your own more professional TTS software. But citizens who are only temporarily or situationally unable to read on-screen text are dependent on the voices coming with the computer’s operating system in their own language.
Considered as pure, disembodied voices, Magnus and Sara might work well for the Danish public authorities: They appear formal, trustworthy, and competent. But, as discussed by Edgar (2019), they do also reproduce cultural norms that privilege certain vocal qualities and identities over others. This is not a problem in itself but should be critically reflected on by the institutions represented by the voices. Otherwise, they naively give the power to big tech to decide how they orally address the citizens and to control their public appearance and integrity. When using TTS tools on different kinds of text and interfaces, it is evident that some written texts and genres work better in audio than others. Technically, there is still a long way to go before the text and visual design on Borger.dk are adaptable to TTS tools.
In the following section I will introduce synthetic orality as a defining feature of the current oral and aural turn and in the section “Cognitive, cultural and social implications of synthetic orality” return to discuss the case study.
Synthetic orality
Ever since the publication of Orality and Literacy ([1982] 2002), Walter J. Ong has had an enormous influence on the understanding of the term ‘orality’. As Paula McDowell argues in her essay “Ong and the concept of orality” (2012), scholars working in media studies and related fields addressing orality are often more familiar with Ong’s distinctive coinages of the term than they are with the etymology of the word. I share her ambition of calling for renewed critical attention to the complexity and ubiquity of orality in media studies in general (McDowell 2012: 177) and in digital, synthetic orality in particular.
Ong uses the term in relation to what he calls oral cultures, which are cultures based on spoken communication. He differentiates between primary orality as thought and expression untouched by the culture of writing and print, and secondary orality as oral culture defined and implicitly influenced by the written and printed word, and includes oral culture made possible by technology, including “the orality of telephones, radio and television which depends on writing and print for its existence” (Ong 2012: 3). Ong transcends the understanding of orality as a purely sonic, by-mouth-spoken and by-ear-listening practice into a mode of consciousness and cultural perception. As McDowell writes, “the subject of Orality and Literacy is a cognitive shift rather than social, political, or religious history” (McDowell 2012: 173). According to Ong, oral cultures exhibit distinctive ways of acquiring, managing, and verbalizing knowledge that the introduction of writing changed radically. What we are witnessing now is, in reverse, how the oral and aural turn in digital communication is radically changing how we access, read, understand, and engage with written digital texts by use of synthetic voices and TTS technologies. This does not mean that we turn away from writing and visual perception, but that synthetic orality and TTS tools in new ways are changing how we manage and understand born-written information and knowledge.
Etymologically, oral means ‘mouth’ and orality is loosely used as a synonym for oral communication, which in everyday contexts refers to speech. In that sense I suggest a basic understanding of the term synthetic orality as a ‘technologically mediated digital orality’ including TTS technology and synthetic voices, and both AI voices trained on real human voices (cyborgs) and pure synthetic robotic voices. Synthetic orality is an emergent category of digital voice-based communication produced by machines, designed to simulate human vocal characteristics, yet originating from no physical body at the time spoken. From this follows that perceptions of sounds of the human mouth, tongue, breathing, and vocal cords are not emanating from an actual body but imitated, which necessarily reconfigures the cognitive schemas used in voice perception. However, in dialogue with Walter J. Ong I aim to develop a theoretical construct around the concept synthetic orality that not only includes this basic understanding of synthetic orality as technologically mediated synthetic speech but also as a culture of perception including cognitive, cultural, and social implications.
I am not the first to suggest an updated version of Ong’s oralities to a tertiary orality of digital media. Finnemann (2005) uses the term to describe digitized speech, synthetic speech, voice response systems, speech recognition systems, etc., and Robert K. Logan (2010) suggests a tertiary orality or digital orality based on the conversational nature of text-based Internet communication. According to Logan, this would include the orality of e-mails, blog posts, list services, and text messaging: written text transmitted through the Internet (Logan 2010, 103). Don-Hoo Lee also uses the term tertiary orality about words presented in multimodal forms, where sound, text, and image are combined (Lee 2013: 176). Emma Rodero uses the term digital orality and defines it as “characterised by four factors: use of technology, long-distance transmission on a mass scale, storage and reproduction capacity and possibilities of interaction” (Rodero 2018: 77). In all these cases, orality is used metaphorically, including digital communication forms that are not aural. Only Finnemann uses the term synthetic orality, but he neither elaborates the term further in relation to sound.
In my understanding, orality must necessarily be aural (hearable) and perceived as expressions of some kind of imagined ‘mouth’. Compared to human orality, synthetic orality decenters human agency: Orality becomes a hybrid event co-authored by human intention and machine execution. Synthetic orality elevates “configurability” as a new form of vocal craft and writing with voices becomes writing in speech synthesis markup language (SSML), choosing voice fonts, and curating stylistic-, genre-, and emotional profiles. When listening to synthetic voices like Magnus and Sara, synthetic orality includes a “perceptual adaptation” where listeners develop new auralities and adapt to new synthetic dialects to decode synthetic prosody and filter out digital noise, flaws, and glitches.
I have in this article only introduced synthetic orality as a tentative programmatic framework, which can be developed in many different directions. In the following section I will elaborate it in the direction of the aim of this specific article by using what I call sound-sociological terms to address some of the democratic and social implications related to the case study of Borger.dk.
Democratic and social implications of synthetic orality at Borger.dk
In the following I will connect the democratic implications of synthetic orality to three interrelated perspectives: 1) Hartmut Rosa’s very hyped concept of resonance from the book Resonance: A Sociology of Our Relationship to the World (2016), 2) Kate Lacey’s notion of the listening publics from the book Listening Publics: The Politics and Experience of Listening in the Media Age (2013), and 3) sonic citizenship as developed by Højlund, Vandsø, and Breinbjerg’s article in Danish “Det soniske medborgerskab” (2021).
To listen to voices, and to have a general listening attitude to the world, are key in our understanding of publics and democracies, and Rosa uses the word ‘resonance’ metaphorically to describe this desirable open and attentive disposition to the world: “Democracy only works, I claim, when it functions as a sphere of resonance” (Rosa in Zaretsky 2017) (6). Hartmut Rosa’s concept of resonance directs attention to communication as relation rather than mere transmission. Resonance concerns whether an address is experienced as meaningful, responsive, and capable of eliciting a response. In the Borger.dk case, the issue is therefore not only whether the citizen can hear the words, but whether the auditory form of the state’s address feels attuned to the citizen’s need for orientation and action. When synthetic speech is mechanically stressed, tonally awkward, or poorly aligned with the logic of the visual interface, the problem is not only confusion. It may also produce a sense of institutional distance: the state speaks but does not quite address.
Rosa’s concept resonates very well with Kate Lacey’s ideas of listening publics. To Lacey, being a listening citizen is a kind of anticipatory disposition that is defined by an openness. However, for Lacey this is a public disposition, not a personal one as in Rosa’s framework. Kate Lacey’s notion of listening publics clarifies a democratic dimension. Lacey’s point is that democratic culture depends not only on the freedom to speak, but on the existence of publics capable of listening (like Rosa, she is using terms related to sound in a broader non-sonic metaphorical sense). Listening is therefore not passive reception, but a civic disposition. In relation to the oral and aural turn, this means that digital citizenship increasingly includes listening as a mode of engaging with public authority. This becomes very concrete in the TTS reading of the text at Borger.dk, where citizens are not only readers of public information, but also listeners. This implies reciprocity. If citizens are addressed as listeners, institutions incur a corresponding obligation to make themselves listenable, which Borger.dk fails to do with the current TTS solution. A voice that sounds oddly paced or tonally misplaced may introduce an affect of inattentiveness into the relation between citizen and institution. Conversely, a voice that sounds smooth and intimate may simulate an attentive call without being able to reciprocate the answer. Synthetic orality therefore opens a field between estrangement and false familiarity. If the voice sounds too machinic, the state risks appearing indifferent; if it sounds too human-like, authority risks becoming uncannily intimate.
The concept of sonic citizenship makes the political stakes sharper by foregrounding power, design, exclusion, and inclusion in the discussion of how synthetic orality, recasts the communication at Borger.dk as an auditory relation. Compared to Rosa and Lacey, sonic citizenship brings us closer to everyday listening behavior, and to morality. Højlund et al. discuss this concept as a combination between right and duty: the right to speak, and the obligation to listen and obey (Højlund, Vandsø, Breinbjerg, 2021: 4). From this perspective, citizenship is not only a matter of rights and duties in the abstract, but also a condition of being addressed and recognized through sound. Read through listening publics and sonic citizenship, citizenship is not just the right to speak but the duty and capacity to hear and respond. Likewise, the state must take a responsibility and duty of calling the citizens with a proper voice. And as the analysis of Borger.dk shows the sovereign voice of Danish public administration is no longer necessarily authored by the institution that speaks. Instead, it is mediated by platforms whose design choices are shaped elsewhere and according to other (commercial) priorities. Avoiding that outcome does not require abandoning synthetic voices. It requires designing online text also for listening and TTS-aware semantics alongside critical reflections of voice design.
Together these overlapping theoretical perspectives can inform the discussion of synthetic orality in relation to the case study of Borger.dk and its democratic implications. It is obvious that the technological development and legal implementation of TTS tools have social and democratic potentials by welcoming another reading preference than eye-reading and by allowing more people to get better access to the information on Borger.dk, which is required as a Danish citizen. The Borger.dk case shows that synthetic orality is not merely a technical accessibility feature but a new communicative layer of governance and mode of engagement, in which citizens encounter the state. That is obviously not considered by the programmers of Borger.dk. What is visually organized becomes aurally compressed. The case therefore shows that visual legibility does not automatically become audio legibility.
Conclusion
Voice as a method and a medium of interacting with digital systems is no longer peripheral but is rapidly consolidating itself as a mainstream interface valued for its convenience and accessibility. The normalization of voice-driven digital behaviors reflects not just technological familiarity, but also a meaningful reorientation in how users expect to interact with the digital world. In high-trust, digital-by-default states like the Danish, the voice of the authorities is part of democratic legitimacy.
TTS expands access for citizens who cannot or do not wish to rely solely on visual reading, and it broadens the modalities through which public information can be reached and acted upon. But that promise can only be realized if listening is treated as a distinct mode of public address, with its own aesthetics, politics, and ethics. A digital democracy cannot simply add synthetic voices to written interfaces and presume that inclusion has thereby been achieved. It must ask what kinds of voices are being added, under whose control, and with what social consequences.
Seen in this light, the Borger.dk case reveals more than a technical limitation in current text-to-speech implementation. It marks a broader historical shift. As synthetic orality becomes a routine interface in public administration, the question is no longer only how the state communicates through text, but how it sounds. The oral turn in digital governance is therefore not simply about hearing written language aloud. It is about hearing the state differently.
Acknowledgements
This article is supported by Aarhus University Research Foundation and Aarhus Institute of Advanced Studies through the AIAS-SHAPE Fellowship at Aarhus University, Resonating synthetic voices and listening citizens: Democratic implications of TTS-assisted communication (2024-2025), aias.au.dk/aias-fellows/former-fellows/former-fellows-archive/iben-have. SHAPE – Shaping Digital Citizenship is an interdisciplinary research center promoting democracy and citizenship in a world of data, algorithms, and artificial intelligence, shape.au.dk/en/.
- 1
Mordor Intelligence is an established commercial market-research firm that produces industry analyses and market forecasts. According to its own methodology descriptions, its research draws on secondary data and expert interviews, often alongside triangulation and other validation methods.
- 2
In spring and summer 2026, I am carrying out the dissemination project Stemmeboxen: Når online-tekst bliver til syntetisk tale [The Voice Ballot: when online text becomes synthetic speech], supported by the Carlsberg Foundation (https://projekter.au.dk/stemmeboxen). Using an interactive physical installation, the project invites Danish citizens to listen to two AI voices recommended by Danish municipalities and to assess them through a screen-based interface. This project provides distinctive empirical material that in the future enables me to deepen and qualify the conceptual analysis presented in this article.
- 3
At Borger.dk all content is written in Danish, and there is no option for changing language on the platform. However, there exists an English subsite called Lifeindenmark.dk providing information but no self-service for visitors and foreign citizens.
- 4
https://www.borger.dk/transport-trafik-rejser/Pas/Ansoeg-om-eller-forny-dansk-pas (Accessed March 10, 2026)
- 5
You can chance the voice by entering the System Settings, choose Accessibility, choose Spoken Content and open System Voice/Manage Voices. Apple/macOS offers three Danish voices: Magnus, Sara and Siri. If you use Microsoft, they are called Christel (woman) and Jeppe (man) in Azure/Edge. A quick analysis of other languages in the menu reveals some interesting patterns in relation to the female voices: Anna from Germany and Alice from Italy are like the Danish Sara low-pitched. The Polish (Zosia) and Czech (Zuzana) female voices are middle pitched, and the Hindi (Lekha), Vietnamese (Linh), and Japanese (Kyoko) are high-pitched. In this article the focus is on the voices specifically designed for Danish users. However, a comparative analysis across nations, and cultures could give some interesting insight into design and perception of gendered voices.
- 6
Hartmut Rosa term resonance is not specifically developed in relation to democracies but is more general. However, he uses the term himself in a Keynote address, Conference of European Churches (CEC) General Assembly, Tallinn published in German and English (Rosa 2023). The specific term resonant democracy is also used in ‘Toward a resonant society: An interview with Hartmut Rosa’ (Cassegård et al, 2023).
Keywords
Bibliography
Adgangforalle.dk (n.d.) TTS tool developed by the Special School for Adults, Vendsyssel in collaboration with efaktum Aps, the Technology Centre for the Disabled and Aalborg University. Available at: https://www.adgangforalle.dk/default.efact?pid=7942&mid=0&hid=3213&sub=3213&main=3213 (Accessed: 12 September 2025).
Andrisanis, V. (2017) Inventing Havana in Thin Air: Sound, Space, and the Making of Sonic Citizenship. PhD thesis. Simon Fraser University.
Aylett, M.P, Sutton, S.J., and Vazquez-Alvarez, Y. (2019) "The Right Kind of Unnatural: Designing a Robot Voice". In Proceedings of the 1st International Conference on Conversational User Interfaces (CUI ’19). ACM, New York, NY, USA, 25:1–25:2. doi: dx.doi.org/10.1145/3342775.3342806
Baird, A., et al. (2018) "The Perception of Vocal Traits in Synthesized Voices: Age, Gender, and Human-Likeness". In Journal of the Audio Engineering Society 66 (4), pp 1-9. doi: doi.org/10.17743/jaes.2018.0023
Brooks, A.W., Huang, L., Kearney, S.W. and Murray, F.E. (2014) "Investors prefer entrepreneurial ventures pitched by attractive men". In Proceedings of the National Academy of Sciences, 111(12), pp. 4427–4431. doi: doi.org/10.1073/pnas.1321202111
Cambre, J. and Kulkarni, C. (2019) "One voice fits all? Social implications and research challenges of designing voices for smart devices". In Proceedings of the ACM on Human-Computer Interaction (CSCW).
Cambre, J., Maddock, J. and Kaye, J.T.J. (2020) "Choice of voices: a large-scale evaluation of text-to-speech voice quality for long-form content", In Proceedings of the 2020 CHI Conference on Human Factors in Computing Systems (CHI ’20). New York: ACM.
Cassegård, C., Malmqvist, K. and Ståhl, C. (2023) "Toward a resonant society: an interview with Hartmut Rosa". In Sociologisk Forskning, 60(2), pp. 177–195. doi: doi.org/10.37062/sf.60.25492
Cavarero, A. (2005) For more than one voice: toward a philosophy of vocal expression. Stanford, CA: Stanford University Press.
Collective M. (2021) "The generation of a [multi’vocal] voice" (audio paper) Seismograf, doi: 10.48233/SEISMOGRAF2612.
Diel, A. and Lewis, M. (2024) "Deviation from typical organic voices best explains a vocal uncanny valley". In Computers in Human Behavior Reports, 14, 100430. doi: doi.org/10.1016/j.chbr.2024.100430
Edgar, A.N. (2019) Culturally speaking: the rhetoric of voice and identity in a mediated culture. Columbus: The Ohio State University Press.
Engberg, M., Have, I. and Stougaard Pedersen, B. (eds.) (2023) The digital reading condition. New York: Routledge.
European Commission (n.d.a) "Web accessibility directive – standards and harmonisation". Available at: https://digital-strategy.ec.europa.eu/en/policies/web-accessibility-directive-standards-and-harmonisation (Accessed: 12 May 2025).
European Commission (n.d.b) "European accessibility act (EAA)". Available at: https://commission.europa.eu/strategy-and-policy/policies/justice-and-fundamental-rights/disability/european-accessibility-act-eaa_en
Feld, S. (1996) "Waterfalls of song: an acoustemology of place resounding in Bosavi, Papua New Guinea". In Feld, S. and Basso, K.H. (eds.) Senses of place. Santa Fe, NM: School of American Research Press, pp. 91–136.
Finnemann, N. O. (2005). Internettet i mediehistorisk perspektiv. København: Samfundslitteratur.
Freud, S. (1919) "Das Unheimliche". In Imago, 5(5–6), pp. 297–324.
Gautier, A.M.O. (2014) Aurality: listening and knowledge in nineteenth-century Colombia. Durham: Duke University Press.
Have, I. and Stougaard Pedersen, B. (2016) Digital audiobooks: new media, users, and experiences. New York: Routledge.
Have, I. (2008) "Background music and background feelings: background music in audio-visual media". In Journal of Music and Meaning, 6. Available at: http://www.musicandmeaning.net/issues/showArticle.php?artID=6.5 (Accessed: 13 September 2025).
Have, I. (2023) "Motivations for everyday audiobook reading". In Engberg, M., Have, I. and Stougaard Pedersen, B. (eds.) The digital reading condition. New York: Routledge.
Have, I. (2024) Lydmedier: teori og analyse. København: Samfundslitteratur.
Have, I. (forthcoming) Reading with ears and writing with voices: the aural and oral turn in digital communication and media culture.
Holliday, N. (2023) "Siri, you’ve changed! Acoustic properties and racialized judgments of voice assistants". In Frontiers in Communication. doi: doi.org/10.3389/fcomm.2023.1116955
Højlund, M.K, Vandsø, A. & Breinbjerg, M. (2021) "Det soniske medborgerskab". In Kulturstudier, 12(2), pp. 94 – 117. doi: doi.org/10.7146/ks.v12i2.129569
Jones, A. and Zellou, G. (2024) "Voice accentedness, but not gender, affects social responses to a computer tutor". In Frontiers in Computer Science, 6, 1436341. doi: doi.org/10.3389/fcomp.2024.1436341
Hasse Jørgensen, S. M. (2020) Vocal Bodies: Performing Paralinguistic Stereotypes and Multivocalities in Art and Digital Media. Ph.D.-dissertation Copenhagen University.
Kang, W., Hughes, M. and Roy, D. (2024) "Anonymization of Voices in Spaces for Civic Dialogue: Measuring Impact on Empathy, Trust, and Feeling Heard". In Proceedings of the ACM on Human-Computer Interaction.
Keelor, J., Ellis, D. and Olson, J. (2020) "The use of text-to-speech technology by postsecondary students with print disabilities", In Assistive Technology Outcomes and Benefits, 14(2).
Kim, M., Park, J., Jeong, M., Song J. (2024) "Personality perception in synthetic versus natural speech: The effects of voice quality and prosody". In Journal of the Acoustical Society of America. doi: doi.org/10.1121/10.0027729
Kim, M., Park, J., Jeong, M., Song J. (2025) "What Determines Personality Impressions of Synthetic and Natural Voices? The Effects of Voice Quality and Intonation". In Language and Speech. doi: doi.org/10.1177/00238309251389567
Kumar, N. (2025) "68 voice search statistics 2025: usage data and trends". Available at https://www.demandsage.com/voice-search-statistics/ (Accessed: 12 May 2025).
Lacey, K. (2013) Listening publics: the politics and experience of listening in the media age. Cambridge: Polity.
Lacey, K. (2014) "Listening overlooked: an audit of listening as a category in the public sphere". In Javnost – The Public, 18(4), pp. 5–20. doi: doi.org/10.1080/13183222.2011.11009064
Lee, D.-H. (2013) "Mobile snapshots: pictorial communication in the age of tertiary orality". In Wise, J.M. (ed.) New visualities, new technologies. New York: Taylor & Francis.
Lee, E.J., Nass, C. and Brave, S. (2000) "Can computer-generated speech have gender?". In CHI ’00 Extended Abstracts. New York: ACM, pp. 289–290.
Logan, R. K. (2010). Understanding new media: Extending Marshall McLuhan. New York: Peter Lang Publishing.
Lønstrup, A. (2004) Stemmen og øret – studier i vokalitet og auditiv kultur. Aarhus: Klim.
McAleer, P., Todorov, A. and Belin, P. (2014) "How do you say “Hello”?". In PLOS ONE, 9(3), e90779. doi: doi.org/10.1371/journal.pone.0090779
McDowell, P. (2012) "Ong and the concept of orality". In Religion and Literature, 44(2), pp. 169–178.
McDowell, P. and Ignacio, L. (2023) "Synthetic versus human voices in audiobooks". In New Media & Society, 25(7), pp. 1746–1764. doi: /doi.org/10.1177/14614448211024142
Moore, R.K. (2017a) "Appropriate voices for artefacts". In Proceedings of Vocal Interactivity Workshop.
Moore, R.K. (2017b) "Is spoken language all-or-nothing?". In Jokinen, K. and Wilcock, G. (eds.) Dialogues with social robots. Singapore: Springer, pp. 281–291. doi: doi.org/10.1007/978-981-10-2585-3_22
Mooshammer, S., Etzrodt, K. and Weidmüller, L. (2025) "Trust in gendered voice assistants". In Publizistik. doi: doi.org/10.1007/s11616-025-00907-5
Mordor Intelligence (2024) "Text-to-speech market report (2024–2029)". Available at: https://www.mordorintelligence.com/industry-reports/text-to-speech-market (Accessed: 20 March 2026).
Mori M. (1970), "The Uncanny Valley" Translated by Karl F. MacDorman and Takashi Minato. In Energy, 7(4), pp. 33-35.
Nass, C. and Lee, K.M. (2001) "Does computer-synthesized speech manifest personality?". In Journal of Experimental Psychology: Applied, 7(3).
Nass, C. and Brave, S. (2005) Wired for speech. Cambridge, MA: MIT Press.
Ong, W.J. (2012) Orality and literacy. London: Routledge. (Originally published 1982).
Phan, T. (2017) "The materiality of the digital and the gendered voice of Siri". In Transformations, 29.
Rodero, E. (2018) "The growing importance of voice and sound". In AC/E Digital Culture Annual Report. Available at: https://emmarodero.com/wp-content/uploads/2018/07/The-growing-importance-of-voice-and-sound-in-the-digital-age.pdf
Robin, J. (2019) The sonic episteme: acoustic resonance, neoliberalism, and biopolitics. Durham: Duke University Press.
Rosa, H. (2021) Resonance: a sociology of our relationship to the world. Cambridge: Polity.
Rosa, H. (2023) "Being European – A Sociological Assessment 2023 and Beyond". Keynote address, Conference of European Churches (CEC) General Assembly, Tallinn, 16 June. https://ceceurope.org/storage/app/media/Key-speech-CEC-Assembly-2023-Hartmut%20Rosa-en.pdf. In German: https://ceceurope.org/storage/app/media/Key-speech-CEC-Assembly-2023-Hartmut%20Rosa-de.pdf (Accessed September 14. 2025).
Schibsted Global Brand Team (2023) Schibsted future report 2024. Available at: https://futurereport.schibsted.com/downloads/schibsted_future_report_2024.pdf
Shen, J. et al. (2018) "Natural TTS synthesis by conditioning WaveNet on mel-spectrogram predictions". In ICASSP 2018. IEEE, pp. 4779–4783.
Taylor, P. (2009) Text-to-speech synthesis. Cambridge: Cambridge University Press.
Tsantani, M.S. et al. (2016) "Low vocal pitch preference drives first impressions irrespective of context in male voices but not in female voices". In Perception, 45(8), pp. 946–963. doi: doi.org/10.1177/0301006616643675
West, M., Kraut, R. and Chew, H.E. (2019) I’d blush if I could. Paris: UNESCO. https://doi.org/10.54675/RAPC9356
Zaretsky, E. (2017) "The crisis of dynamic stabilization and the sociology ofr. An Interview with Hartmut Rosa", January 18, 2017, https://publicseminar.org/2017/01/the-crisis-of-dynamic-stabilization-and-the-sociology-of-resonance/ (Accessed: 12 May 2025).